Configuring parameter values
You must be a database or organization administrator to modify these settings.- From the PlanetScale organization dashboard, select the desired database
- Navigate to the Clusters page from the menu on the left
- Choose the branch whose parameters you’d like to configure in the “Branch” dropdown
- Select the Parameters tab
- Search for a specific parameter or scroll through the page to see all configurable parameters
- Update the value for the parameter(s) you wish to adjust
- Click “Queue parameter changes”
- Once you’re ready to apply the changes, click “Apply changes”
Tracking changes to parameters
You can click on the “Changes” tab on the Clusters page to view a log of any changes made to your parameter settings. The log will include the settings affected, the original and updated values, status, user that made the changes, start time, and end time.When updating a cluster’s size, some parameters will automatically
be adjusted. Each cluster size is associated with default parameter settings, changing the cluster size will also
update those defaults. The exception to this is if you manually override a default parameter setting. In that case, a
cluster size adjustment will not automatically change that setting.
Parameter change types
PostgreSQL parameter changes fall into two categories based on how they are applied:- Reloadable changes: The parameter can be updated without restarting PostgreSQL, resulting in zero downtime
- Restart-required changes: PostgreSQL requires a cluster restart for the parameter to take effect
Restart behavior for production clusters
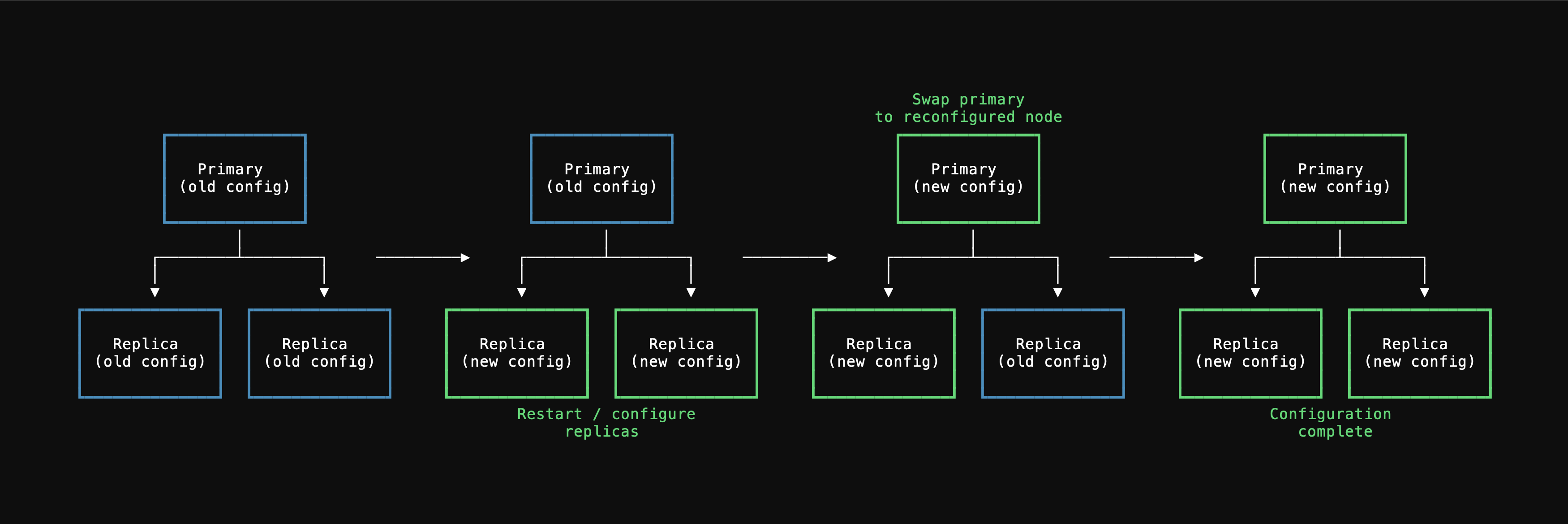
When you apply parameters that require a restart, PlanetScale performs a rolling restart process to minimize downtime:- Configuration changes are first applied to replica instances and they are restarted
- Once replicas are ready, a switchover promotes one replica to become the new primary
- The configuration is applied to the former primary (now a replica) and it is restarted
Number of processes parameter for PgBouncer, PgBouncer connections persist through all parameter changes and do not require reconnection.
Some parameters are required by PostgreSQL to be applied to the primary before replicas, which may result in a slightly longer unavailability period.
Default parameter values
The following table shows the default values for parameters that are displayed by default to customers. You can find additional parameters in the search field.| Parameter | Restart Required | Description |
|---|---|---|
| PgBouncer | ||
| Number of processes | ✅ (restarts PGBouncer only) | Sets the number of PgBouncer processes that will run on each node in this branch’s cluster |
| default_pool_size | Sets the number of server connections to allow per user/database pair | |
| max_client_conn | Sets the maximum number of client connections allowed | |
| max_db_client_connections | Sets the maximum number of client connections allowed per database (regardless of user). 0 is unlimited | |
| max_db_connections | Sets the maximum number of server connections allowed per database (regardless of user). 0 is unlimited | |
| max_prepared_statements | Sets the maximum number of client-prepared statements available across server connections | |
| max_user_connections | Sets the maximum number of server connections allowed per user (regardless of database). 0 is unlimited | |
| server_lifetime | Sets how long an unused server connection stays open | |
| server_idle_timeout | Sets how long an idle server connection stays open | |
| Resource usage | ||
| effective_io_concurrency | Sets the number of simultaneous requests that can be handled efficiently by the disk subsystem | |
| effective_cache_size | Sets the planner’s assumption about the total size of the data caches | |
| huge_pages | ✅ | Controls whether huge pages are requested for the main shared memory area |
| maintenance_io_concurrency | Sets the number of simultaneous requests that can be handled efficiently by the disk subsystem for maintenance operations | |
| maintenance_work_mem | Sets the maximum memory to be used for maintenance operations | |
| max_parallel_maintenance_workers | Sets the maximum number of parallel processes per maintenance operation | |
| max_parallel_workers | Sets the maximum number of parallel workers that can be active at one time | |
| max_parallel_workers_per_gather | Sets the maximum number of parallel processes per executor node | |
| max_worker_processes | ✅ | Sets the maximum number of background processes that the cluster can support |
| shared_buffers | ✅ | Sets the amount of memory the database server uses for shared memory buffers |
| work_mem | Sets the amount of memory the database will use for internal operations like sorting and hashing | |
| Write-ahead log | ||
| max_slot_wal_keep_size | Sets the maximum WAL size that can be reserved by replication slots | |
| max_wal_size | Sets the WAL size that triggers a checkpoint | |
| min_wal_size | Sets the minimum size to shrink the WAL to | |
| wal_buffers | ✅ | Sets the number of disk-page buffers in shared memory for WAL |
| wal_level | ✅ | Sets the level of information written to the WAL |
| Query tuning | ||
| deadlock_timeout | Sets the maximum time to wait on a lock before checking for deadlocks | |
| default_statistics_target | Sets the default statistics target for table columns without a column-specific target set | |
| random_page_cost | Sets the planner’s estimate of the cost of a nonsequentially fetched disk page | |
| seq_page_cost | Sets the planner’s estimate of the cost of a sequentially fetched disk page | |
| Connections and authentication | ||
| max_connections | ✅ | Sets the maximum number of concurrent connections |
| Replication | ||
| hot_standby_feedback | Sends feedback to the primary about queries being executed on the standby. Required for logical replication failover | |
| max_logical_replication_workers | ✅ | Sets the maximum number of logical replication workers |
| max_replication_slots | ✅ | Sets the maximum number of replication slots that the server can support |
| max_sync_workers_per_subscription | Sets the maximum number of synchronization workers per subscription | |
| max_wal_senders | ✅ | Sets the maximum number of WAL senders |
| sync_replication_slots | Enables standbys to synchronize logical replication streams from the primary. Required for logical replication failover | |
| Failover | ||
| failover_delay | Sets the time to wait before triggering a failover to drain inflight transactions | |
| Statistics | ||
| track_io_timing | Enables timing of database I/O calls. This may cause significant overhead | |
| Logging | ||
| log_lock_waits | Logs the duration of lock waits that exceed the deadlock_timeout | |
| log_min_duration_statement | Sets the minimum execution time above which all statements will be logged | |
| Client connection defaults | ||
| shared_preload_libraries | ✅ | Specifies shared libraries to preload into the server at server start |
| Autovacuum | ||
| autovacuum_vacuum_scale_factor | Specifies a fraction of the table size to add to autovacuum_vacuum_threshold when deciding whether to trigger a VACUUM | |
| autovacuum_analyze_scale_factor | Specifies a fraction of the table size to add to autovacuum_analyze_threshold when deciding whether to trigger an ANALYZE |